Blocks Module
The blocks module provides the fundamental neural network building blocks used in PyNAS architecture search. These modules include various convolution types, activation functions, pooling layers, and specialized heads for different tasks.
Overview
The blocks module is organized into several submodules:
Convolutions: Various convolution blocks including classic, mobile, residual, and dense variants
Activations: Activation functions like ReLU, GELU, Sigmoid, and Softmax
Pooling: Max and average pooling operations
Heads: Classification and segmentation heads for different tasks
Residual: Residual connection utilities and implementations
Convolution Blocks
- class pynas.blocks.convolutions.ConvAct(in_channels, out_channels, kernel_size=3, stride=1, padding=1, activation=ReLU)[source]
Bases:
Sequential
- class pynas.blocks.convolutions.ConvBnAct(in_channels, out_channels, kernel_size=3, stride=1, padding=1, activation=ReLU)[source]
Bases:
Sequential
- class pynas.blocks.convolutions.SEBlock(in_channels, reduction=16)[source]
Bases:
Module- __init__(in_channels, reduction=16)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.ConvSE(in_channels, out_channels, kernel_size=3, stride=1, padding=1, activation=ReLU)[source]
Bases:
Sequential
- class pynas.blocks.convolutions.MBConv(in_channels, out_channels, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Bases:
Module- __init__(in_channels, out_channels, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.MBConvNoRes(in_channels, out_channels, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Bases:
Module- __init__(in_channels, out_channels, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.CSPConvBlock(in_channels, num_blocks=1, activation=ReLU)[source]
Bases:
Module- __init__(in_channels, num_blocks=1, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.CSPMBConvBlock(in_channels, num_blocks=1, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Bases:
Module- __init__(in_channels, num_blocks=1, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.DenseNetBlock(in_channels, out_channels, activation=ReLU)[source]
Bases:
ModuleBasic DenseNet block composed by one 3x3 convs with residual connection. The residual connection is perfomed by concatenate the input and the output.
- __init__(in_channels, out_channels, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.ResNetBasicBlock(in_channels, out_channels, reduction_factor=4, activation=ReLU)[source]
Bases:
Module- __init__(in_channels, out_channels, reduction_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.ResNetBlock(in_channels, out_channels, reduction_factor=4, activation=ReLU)[source]
Bases:
Module- __init__(in_channels, out_channels, reduction_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.Upsample(scale_factor=2, mode='nearest')[source]
Bases:
Module- __init__(scale_factor=2, mode='nearest')[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Classic Convolution Blocks
- class pynas.blocks.convolutions.ConvAct(in_channels, out_channels, kernel_size=3, stride=1, padding=1, activation=ReLU)[source]
Bases:
SequentialBasic convolution followed by activation.
- class pynas.blocks.convolutions.ConvBnAct(in_channels, out_channels, kernel_size=3, stride=1, padding=1, activation=ReLU)[source]
Bases:
SequentialConvolution, batch normalization, and activation in sequence.
- class pynas.blocks.convolutions.ConvSE(in_channels, out_channels, kernel_size=3, stride=1, padding=1, activation=ReLU)[source]
Bases:
SequentialConvolution with Squeeze-and-Excitation attention mechanism.
Squeeze-and-Excitation Block
- class pynas.blocks.convolutions.SEBlock(in_channels, reduction=16)[source]
Bases:
ModuleSqueeze-and-Excitation block for channel attention.
- __init__(in_channels, reduction=16)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Mobile Convolution Blocks
- class pynas.blocks.convolutions.MBConv(in_channels, out_channels, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Bases:
ModuleMobile Inverted Bottleneck Convolution with residual connection.
- __init__(in_channels, out_channels, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.MBConvNoRes(in_channels, out_channels, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Bases:
ModuleMobile Inverted Bottleneck Convolution without residual connection.
- __init__(in_channels, out_channels, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
CSP Blocks
- class pynas.blocks.convolutions.CSPConvBlock(in_channels, num_blocks=1, activation=ReLU)[source]
Bases:
ModuleCross Stage Partial convolution block for efficient feature learning.
- __init__(in_channels, num_blocks=1, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.CSPMBConvBlock(in_channels, num_blocks=1, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Bases:
ModuleCSP block using Mobile Inverted Bottleneck convolutions.
- __init__(in_channels, num_blocks=1, dw_kernel_size=3, expansion_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Dense and Residual Blocks
- class pynas.blocks.convolutions.DenseNetBlock(in_channels, out_channels, activation=ReLU)[source]
Bases:
ModuleBasic DenseNet block composed by one 3x3 convs with residual connection. The residual connection is perfomed by concatenate the input and the output.
DenseNet block with concatenation-based feature reuse.
- __init__(in_channels, out_channels, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.ResNetBasicBlock(in_channels, out_channels, reduction_factor=4, activation=ReLU)[source]
Bases:
ModuleBasic ResNet block with bottleneck structure.
- __init__(in_channels, out_channels, reduction_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.convolutions.ResNetBlock(in_channels, out_channels, reduction_factor=4, activation=ReLU)[source]
Bases:
ModuleResNet block with residual connection.
- __init__(in_channels, out_channels, reduction_factor=4, activation=ReLU)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Utility Blocks
- class pynas.blocks.convolutions.Upsample(scale_factor=2, mode='nearest')[source]
Bases:
ModuleUpsampling layer for increasing spatial resolution.
- __init__(scale_factor=2, mode='nearest')[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Activation Functions
- class pynas.blocks.activations.GELU(*args, **kwargs)[source]
Bases:
ModuleGaussian Error Linear Unit (GELU) activation function. This module implements the GELU activation function, which is used to introduce non-linearity in the network. GELU is a smooth, non-monotonic function that models the Gaussian cumulative distribution function. It is commonly used in transformer architectures and other advanced models.
- Parameters:
x (Tensor) – Input tensor to which the GELU activation function is applied.
- Returns:
Output tensor after applying the GELU activation function.
- Return type:
Tensor
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.activations.ReLU(*args, **kwargs)[source]
Bases:
ModuleRectified Linear Unit (ReLU) activation function. This module implements the ReLU activation function, which is widely used in neural networks for introducing non-linearity. ReLU is defined as the positive part of its argument, where each element of the input tensor x that is less than zero is replaced with zero. This function increases the non-linear properties of the decision function and the overall network without affecting the receptive fields of the convolution layer.
- Parameters:
x (Tensor) – Input tensor to which the ReLU activation function is applied.
- Returns:
Output tensor after applying the ReLU activation function.
- Return type:
Tensor
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.activations.Sigmoid(*args, **kwargs)[source]
Bases:
ModuleSigmoid activation function.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.activations.Softmax(*args, **kwargs)[source]
Bases:
ModuleSoftmax activation function.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.activations.GELU(*args, **kwargs)[source]
Bases:
ModuleGaussian Error Linear Unit (GELU) activation function. This module implements the GELU activation function, which is used to introduce non-linearity in the network. GELU is a smooth, non-monotonic function that models the Gaussian cumulative distribution function. It is commonly used in transformer architectures and other advanced models.
- Parameters:
x (Tensor) – Input tensor to which the GELU activation function is applied.
- Returns:
Output tensor after applying the GELU activation function.
- Return type:
Tensor
Gaussian Error Linear Unit activation function.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.activations.ReLU(*args, **kwargs)[source]
Bases:
ModuleRectified Linear Unit (ReLU) activation function. This module implements the ReLU activation function, which is widely used in neural networks for introducing non-linearity. ReLU is defined as the positive part of its argument, where each element of the input tensor x that is less than zero is replaced with zero. This function increases the non-linear properties of the decision function and the overall network without affecting the receptive fields of the convolution layer.
- Parameters:
x (Tensor) – Input tensor to which the ReLU activation function is applied.
- Returns:
Output tensor after applying the ReLU activation function.
- Return type:
Tensor
Rectified Linear Unit activation function.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.activations.Sigmoid(*args, **kwargs)[source]
Bases:
ModuleSigmoid activation function.
Sigmoid activation function.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.activations.Softmax(*args, **kwargs)[source]
Bases:
ModuleSoftmax activation function.
Softmax activation function for multi-class classification.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Pooling Operations
- class pynas.blocks.pooling.AvgPool(kernel_size=2, stride=2)[source]
Bases:
SequentialImplements an average pooling layer. This layer applies a 2D average pooling over an input signal (usually an image) represented as a batch of multichannel data. It reduces the spatial dimensions (width and height) of the input by taking the average of elements in a kernel-sized window, which slides over the input data with a specified stride.
Parameters: - kernel_size (int, optional): The size of the window for each dimension of the input tensor. Default is 2. - stride (int, optional): The stride of the window. Default is 2.
- Example Usage:
avg_pool_layer = AvgPool(kernel_size=2, stride=2)
- class pynas.blocks.pooling.MaxPool(kernel_size=2, stride=None, padding=0)[source]
Bases:
SequentialImplements a max pooling layer. This layer applies a 2D max pooling over an input signal (usually an image) represented as a batch of multichannel data. It reduces the spatial dimensions (width and height) of the input by taking the maximum value of elements in a kernel-sized window, which slides over the input data with a specified stride and padding.
Parameters: - kernel_size (int): The size of the window for each dimension of the input tensor. - stride (int, optional): The stride of the window. Defaults to kernel_size if not specified. - padding (int, optional): The amount of padding added to all sides of the input. Default is 0.
- Example Usage:
max_pool_layer = MaxPool(kernel_size=2, stride=2, padding=0)
- class pynas.blocks.pooling.AvgPool(kernel_size=2, stride=2)[source]
Bases:
SequentialImplements an average pooling layer. This layer applies a 2D average pooling over an input signal (usually an image) represented as a batch of multichannel data. It reduces the spatial dimensions (width and height) of the input by taking the average of elements in a kernel-sized window, which slides over the input data with a specified stride.
Parameters: - kernel_size (int, optional): The size of the window for each dimension of the input tensor. Default is 2. - stride (int, optional): The stride of the window. Default is 2.
- Example Usage:
avg_pool_layer = AvgPool(kernel_size=2, stride=2)
Average pooling operation for spatial downsampling.
- class pynas.blocks.pooling.MaxPool(kernel_size=2, stride=None, padding=0)[source]
Bases:
SequentialImplements a max pooling layer. This layer applies a 2D max pooling over an input signal (usually an image) represented as a batch of multichannel data. It reduces the spatial dimensions (width and height) of the input by taking the maximum value of elements in a kernel-sized window, which slides over the input data with a specified stride and padding.
Parameters: - kernel_size (int): The size of the window for each dimension of the input tensor. - stride (int, optional): The stride of the window. Defaults to kernel_size if not specified. - padding (int, optional): The amount of padding added to all sides of the input. Default is 0.
- Example Usage:
max_pool_layer = MaxPool(kernel_size=2, stride=2, padding=0)
Max pooling operation for spatial downsampling.
Head Modules
- class pynas.blocks.heads.Dropout(p=0.5, inplace=False)[source]
Bases:
ModuleDropout layer for regularization in neural networks.
- Parameters:
- __init__(p=0.5, inplace=False)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.heads.MultiInputClassifier(input_shapes, common_dim=256, mlp_depth=2, mlp_hidden_dim=512, num_classes=10, use_adaptive_pool=True, pool_size=(4, 4))[source]
Bases:
ModuleA PyTorch module for a multi-input classifier that processes multiple input tensors with different shapes and combines their features for classification. :param input_shapes: A list of shapes for each input tensor,
excluding the batch dimension. Each shape can be either (C, H, W) for spatial inputs or (D,) for flat vector inputs.
- Parameters:
common_dim (int, optional) – The dimension to which all inputs are projected. Defaults to 256.
mlp_depth (int, optional) – The number of layers in the final MLP classifier. Defaults to 2.
mlp_hidden_dim (int, optional) – The number of hidden units in each MLP layer. Defaults to 512.
num_classes (int, optional) – The number of output classes for classification. Defaults to 10.
use_adaptive_pool (bool, optional) – Whether to apply adaptive average pooling for spatial inputs. Defaults to True.
pool_size (Tuple[int, int], optional) – The target size for adaptive pooling if it is used. Defaults to (4, 4).
input_shapes (List[Tuple[int, ...]])
- projections
A list of projection modules for each input tensor. These modules transform the inputs to the common dimension.
- Type:
nn.ModuleList
- flatten
A module to flatten the projected tensors.
- Type:
nn.Flatten
- classifier
The MLP classifier that processes the concatenated features and outputs class probabilities.
- Type:
nn.Sequential
- forward(inputs
List[torch.Tensor]) -> torch.Tensor: Processes the input tensors, projects them to a common dimension, concatenates their features, and passes them through the MLP classifier to produce the output logits.
- Raises:
ValueError – If an input shape is not supported (e.g., not (C, H, W) or (D,)).
- Parameters:
- __init__(input_shapes, common_dim=256, mlp_depth=2, mlp_hidden_dim=512, num_classes=10, use_adaptive_pool=True, pool_size=(4, 4))[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(inputs)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.heads.Dropout(p=0.5, inplace=False)[source]
Bases:
ModuleDropout layer for regularization in neural networks.
- Parameters:
Dropout layer for regularization.
- __init__(p=0.5, inplace=False)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.heads.Classifier(encoder, dm, verbose=False)[source]
Bases:
objectClassification head that combines encoder with adaptive pooling and linear layers.
- class pynas.blocks.heads.MultiInputClassifier(input_shapes, common_dim=256, mlp_depth=2, mlp_hidden_dim=512, num_classes=10, use_adaptive_pool=True, pool_size=(4, 4))[source]
Bases:
ModuleA PyTorch module for a multi-input classifier that processes multiple input tensors with different shapes and combines their features for classification. :param input_shapes: A list of shapes for each input tensor,
excluding the batch dimension. Each shape can be either (C, H, W) for spatial inputs or (D,) for flat vector inputs.
- Parameters:
common_dim (int, optional) – The dimension to which all inputs are projected. Defaults to 256.
mlp_depth (int, optional) – The number of layers in the final MLP classifier. Defaults to 2.
mlp_hidden_dim (int, optional) – The number of hidden units in each MLP layer. Defaults to 512.
num_classes (int, optional) – The number of output classes for classification. Defaults to 10.
use_adaptive_pool (bool, optional) – Whether to apply adaptive average pooling for spatial inputs. Defaults to True.
pool_size (Tuple[int, int], optional) – The target size for adaptive pooling if it is used. Defaults to (4, 4).
input_shapes (List[Tuple[int, ...]])
- projections
A list of projection modules for each input tensor. These modules transform the inputs to the common dimension.
- Type:
nn.ModuleList
- flatten
A module to flatten the projected tensors.
- Type:
nn.Flatten
- classifier
The MLP classifier that processes the concatenated features and outputs class probabilities.
- Type:
nn.Sequential
- forward(inputs
List[torch.Tensor]) -> torch.Tensor: Processes the input tensors, projects them to a common dimension, concatenates their features, and passes them through the MLP classifier to produce the output logits.
- Raises:
ValueError – If an input shape is not supported (e.g., not (C, H, W) or (D,)).
- Parameters:
Multi-input classifier for handling multiple input tensors with different shapes.
- __init__(input_shapes, common_dim=256, mlp_depth=2, mlp_hidden_dim=512, num_classes=10, use_adaptive_pool=True, pool_size=(4, 4))[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(inputs)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Residual Utilities
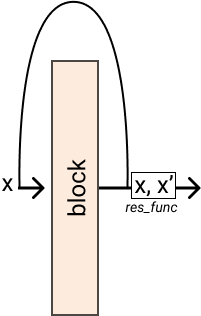
- class pynas.blocks.residual.Residual(block, res_func=None, shortcut=None, *args, **kwargs)[source]
Bases:
ModuleIt applies residual connection to a nn.Module where the output becomes
\(y = F(x) + x\)
Examples
>>> block = nn.Identity() // does nothing >>> res = Residual(block, res_func=lambda x, res: x + res) >>> res(x) // tensor([2])
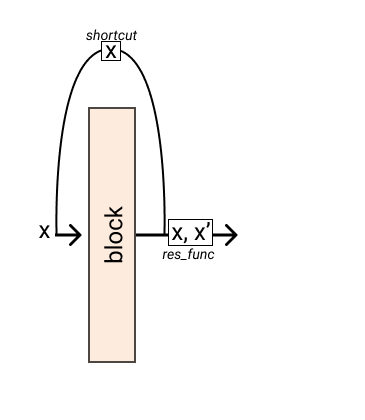
You can also pass a shortcut function
>>> res = Residual(block, res_func=lambda x, res: x + res, shortcut=lambda x: x * 2) >>> res(x) // tensor([3])
- __init__(block, res_func=None, shortcut=None, *args, **kwargs)[source]
- Parameters:
block (nn.Module) – A Pytorch module
res_func (Callable[[Tensor], Tensor], optional) – The residual function. Defaults to None.
shortcut (nn.Module, optional) – A function applied before the input is passed to block. Defaults to None.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.residual.InputForward(blocks, aggr_func)[source]
Bases:
ModuleThis module passes the input to multiple modules and applies a aggregation function on the result.
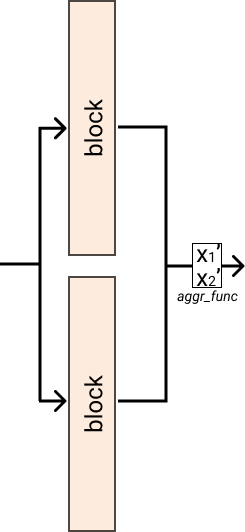
- __init__(blocks, aggr_func)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- pynas.blocks.residual.Cat2d = functools.partial(<class 'pynas.blocks.residual.InputForward'>, aggr_func=<function <lambda>>)
Pass the input to multiple modules and concatenates the output, for 1D input you can use Cat, while for 2D inputs, such as images, you can use Cat2d.
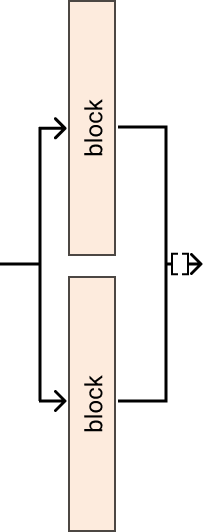
Examples
>>> blocks = nn.ModuleList([nn.Conv2d(32, 64, kernel_size=3), nn.Conv2d(32, 64, kernel_size=3)]) >>> x = torch.rand(1, 32, 48, 48) >>> Cat2d(blocks)(x).shape # torch.Size([1, 128, 46, 46])
- class pynas.blocks.residual.Residual(block, res_func=None, shortcut=None, *args, **kwargs)[source]
Bases:
ModuleIt applies residual connection to a nn.Module where the output becomes
\(y = F(x) + x\)
Examples
>>> block = nn.Identity() // does nothing >>> res = Residual(block, res_func=lambda x, res: x + res) >>> res(x) // tensor([2])
You can also pass a shortcut function
>>> res = Residual(block, res_func=lambda x, res: x + res, shortcut=lambda x: x * 2) >>> res(x) // tensor([3])
Generic residual connection wrapper for any PyTorch module.
- __init__(block, res_func=None, shortcut=None, *args, **kwargs)[source]
- Parameters:
block (nn.Module) – A Pytorch module
res_func (Callable[[Tensor], Tensor], optional) – The residual function. Defaults to None.
shortcut (nn.Module, optional) – A function applied before the input is passed to block. Defaults to None.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
- class pynas.blocks.residual.ResidualAdd(*args, **kwags)[source]
Bases:
ResidualResidual connection with element-wise addition.
- class pynas.blocks.residual.InputForward(blocks, aggr_func)[source]
Bases:
ModuleThis module passes the input to multiple modules and applies a aggregation function on the result.
Module that passes input through multiple modules and aggregates results.
- __init__(blocks, aggr_func)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Utility Functions
Lambda Module
- class pynas.blocks.Lambda(lambd)[source]
Bases:
ModuleAn utility Module, it allows custom function to be passed
- Parameters:
lambd (Callable[Tensor]) – A function that does something on a tensor
Examples
>>> add_two = Lambda(lambd x: x + 2) >>> add_two(Tensor([0])) // 2
Utility module for wrapping custom functions as PyTorch modules.
- __init__(lambd)[source]
Initializes internal Module state, shared by both nn.Module and ScriptModule.
- forward(x)[source]
Defines the computation performed at every call.
Should be overridden by all subclasses.
Note
Although the recipe for forward pass needs to be defined within this function, one should call the
Moduleinstance afterwards instead of this since the former takes care of running the registered hooks while the latter silently ignores them.
Block Configuration
Block Types and Parameters
The following table shows the available block types and their configurable parameters:
Block Type |
Parameters |
|---|---|
ConvAct |
out_channels_coefficient, kernel_size, stride, padding, activation |
ConvBnAct |
out_channels_coefficient, kernel_size, stride, padding, activation |
ConvSE |
out_channels_coefficient, kernel_size, stride, padding, activation |
MBConv |
expansion_factor, dw_kernel_size, activation |
MBConvNoRes |
expansion_factor, dw_kernel_size, activation |
CSPConvBlock |
num_blocks, activation |
CSPMBConvBlock |
expansion_factor, dw_kernel_size, num_blocks, activation |
DenseNetBlock |
out_channels_coefficient, activation |
ResNetBlock |
reduction_factor, activation |
AvgPool |
kernel_size, stride |
MaxPool |
kernel_size, stride |
Dropout |
dropout_rate |
Block Vocabulary
PyNAS uses a vocabulary system for encoding architectures:
Convolution Blocks:
- b: ConvAct
- c: ConvBnAct
- e: ConvSE (with Squeeze-and-Excitation)
- d: DenseNetBlock
- m: MBConv
- n: MBConvNoRes
- R: ResNetBlock
- D: Dropout
Activation Functions:
- r: ReLU
- g: GELU
- sg: Sigmoid
- s: Softmax
Pooling Operations:
- a: AvgPool
- M: MaxPool
Usage Examples
Basic Convolution Block
from pynas.blocks.convolutions import ConvBnAct
from pynas.blocks.activations import ReLU
# Create a convolution block
conv_block = ConvBnAct(
in_channels=32,
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
activation=ReLU
)
# Use in forward pass
output = conv_block(input_tensor)
Mobile Inverted Bottleneck
from pynas.blocks.convolutions import MBConv
from pynas.blocks.activations import ReLU
# Create MBConv block
mb_block = MBConv(
in_channels=64,
out_channels=64,
expansion_factor=4,
dw_kernel_size=3,
activation=ReLU
)
output = mb_block(input_tensor)
Classification Head
from pynas.blocks.heads import Classifier
import torch.nn as nn
# Assume we have a data module with num_classes and input_shape
class SimpleDataModule:
def __init__(self):
self.num_classes = 10
self.input_shape = (3, 224, 224)
# Create encoder (any PyTorch model)
encoder = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d((7, 7))
)
# Create classifier
dm = SimpleDataModule()
classifier = Classifier(encoder=encoder, dm=dm, verbose=True)
# The classifier combines encoder + classification head
output = classifier.model(input_tensor)
Residual Connections
from pynas.blocks.residual import Residual, ResidualAdd
from pynas.blocks.convolutions import ConvBnAct
from pynas.blocks.activations import ReLU
# Create a block with residual connection
conv_block = ConvBnAct(64, 64, activation=ReLU)
residual_block = ResidualAdd(conv_block)
# Or use custom residual function
custom_residual = Residual(
block=conv_block,
res_func=lambda x, res: x + res * 0.5 # Custom weighting
)
output = residual_block(input_tensor)
Architecture Encoding
# Example architecture string: "c3r" means 3 ConvBnAct layers with ReLU
# This gets parsed by the architecture builder into:
architecture = [
{'layer_type': 'ConvBnAct', 'activation': 'ReLU'},
{'layer_type': 'ConvBnAct', 'activation': 'ReLU'},
{'layer_type': 'ConvBnAct', 'activation': 'ReLU'}
]
Best Practices
Channel Management: Use appropriate out_channels_coefficient values to control model complexity
Activation Choice: ReLU for general use, GELU for transformer-like architectures
Pooling Strategy: Use MaxPool for feature extraction, AvgPool before classification
Residual Connections: Essential for deep networks to avoid gradient vanishing
Mobile Blocks: Use MBConv for efficient mobile/edge deployments
CSP Blocks: Good balance between efficiency and representational power
Performance Considerations
MBConv: Most parameter-efficient for mobile deployment
ConvBnAct: Standard choice for balanced performance
CSP Blocks: Good for avoiding gradient bottlenecks
DenseNet Blocks: High memory usage but strong feature reuse
ResNet Blocks: Stable training for very deep networks
The blocks in this module are designed to be modular and composable, allowing the genetic algorithm to efficiently explore different architectural combinations while maintaining compatibility across different block types.